
១. សេចក្តីផ្តើម
Retrieval Augmented Generation (RAG) គឺជាវិធីសាស្ត្រដ៏សំខាន់មួយក្នុងវិស័យបញ្ញាសិប្បនិម្មិត និងការ Natural Language Processing (NLP) ដែលបញ្ចូលគ្នារវាងអានុភាពនៃ Large Language Model ជាមួយនឹងសមត្ថភាពក្នុងការចូលប្រើប្រាស់និងប្រើប្រាស់ចំណេះដឹងខាងក្រៅ។ បច្ចេកទេសថ្មីនេះដោះស្រាយនូវដែនកំណត់សំខាន់ៗនៃ Language Model ដោយបង្កើនសមត្ថភាពរបស់ពួកគេក្នុងការផ្តល់ព័ត៌មានដែលត្រឹមត្រូវ ទាន់សម័យ និងពាក់ព័ន្ធតាមបរិបទ។ ដូចដែល AI បន្តវិវត្តន៍ RAG ឈរនៅជួរមុខនៃការបំពេញគម្លាតរវាងមូលដ្ឋានចំណេះដឹងដ៏ធំធេង និងការបង្កើតភាសាដោយស្វ័យប្រវត្តិ។
២. តើអ្វីទៅជា Retrieval Augmented Generation (RAG)?
RAG គឺជាគំរូ AI មួយដែលរួមបញ្ចូលសមាសភាគសំខាន់ពីរ៖
១. ប្រព័ន្ធទាញយកមួយដែលស្វែងរក និងទាញយកព័ត៌មានដែលពាក់ព័ន្ធពីសំណុំទិន្នន័យដ៏ធំមួយ។
២. Language Model មួយដែលផលិតអត្ថបទដូចមនុស្សដោយផ្អែកលើការណែនាំដែលបានផ្តល់ឱ្យ។
ការរួមបញ្ចូលគ្នានៃសមាសភាគទាំងនេះអនុញ្ញាតឱ្យ RAG អាចប្រើប្រាស់ចំណេះដឹងខាងក្រៅ ខណៈពេលកំពុងបង្កើតការឆ្លើយតប ដែលធ្វើឱ្យគុណភាព និងភាពត្រឹមត្រូវនៃលទ្ធផលរបស់វាមានការកែលម្អគួរឱ្យកត់សម្គាល់។ ខុសពី Language Model បែបប្រពៃណីដែលពឹងផ្អែកតែលើចំណេះដឹងដែលបានបណ្តុះបណ្តាលជាមុន RAG អាចចូលប្រើប្រាស់ និងរួមបញ្ចូលព័ត៌មានដែលពាក់ព័ន្ធបំផុត និងទាន់សម័យពីមូលដ្ឋានចំណេះដឹងរបស់វា។
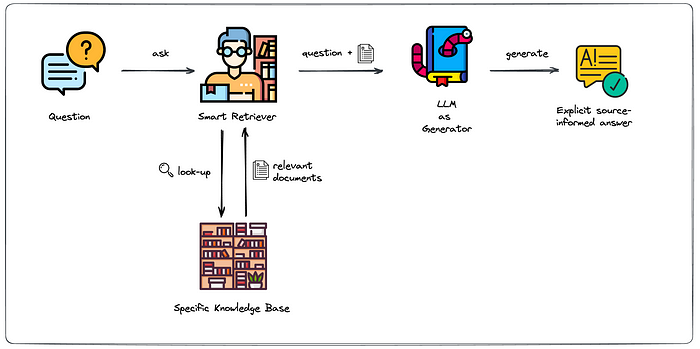
៣. របៀបដែល RAG ដំណើរការ
ដំណើរការ RAG អាចត្រូវបានបំបែកទៅជាបីជំហានសំខាន់ៗ៖
ក) ដំណើរការទាញយក៖
- នៅពេលផ្តល់ជូននូវសំណួរឬការណែនាំ សមាសភាគទាញយកស្វែងរកក្នុងមូលដ្ឋានចំណេះដឹងរបស់វា។
- វាកំណត់ និងទាញយកចំណែកព័ត៌មានដែលពាក់ព័ន្ធបំផុតទាក់ទងនឹងសំណួរ។
- នេះជារឿយៗពាក់ព័ន្ធនឹងបច្ចេកទេសស្វែងរកអត្ថន័យ ដោយប្រើ Embedding ដើម្បីស្វែងរកមាតិកាដែលមានបរិបទស្រដៀងគ្នា។
ខ) ដំណើរការបង្កើត៖
- ព័ត៌មានដែលបានទាញយកត្រូវបានបញ្ជូនទៅគំរូភាសាបង្កើតជាមួយនឹងសំណួរដើម។
- គំរូនេះប្រើបរិបទនេះដើម្បីបង្កើតការឆ្លើយតប ដោយពិចារណាទាំងចំណេះដឹងដែលបានបណ្តុះបណ្តាលជាមុន និងព័ត៌មានដែលទើបទាញយកថ្មីៗ។
គ) ការរួមបញ្ចូលព័ត៌មានដែលបានទាញយក៖
- ដំណើរការបង្កើតរួមបញ្ចូលព័ត៌មានដែលបានទាញយកទៅក្នុងការឆ្លើយតបយ៉ាងរលូន។
- ការរួមបញ្ចូលគ្នានេះអនុញ្ញាតឱ្យគំរូផ្តល់ចម្លើយដែលទាំងរលូន និងមានមូលដ្ឋានលើការពិតដែលមាននៅក្នុងទិន្នន័យដែលបានទាញយក។
៤. អត្ថប្រយោជន៍នៃ RAG
ក) ភាពត្រឹមត្រូវ និងភាពត្រឹមត្រូវតាមការពិតកាន់តែប្រសើរឡើង៖
- ដោយសារតែការផ្តល់ចម្លើយមានមូលដ្ឋានលើព័ត៌មានដែលបានទាញយក RAG កាត់បន្ថយកំហុសយ៉ាងច្រើន និងកែលម្អភាពត្រឹមត្រូវតាមការពិត។
- វាអាចផ្តល់ព័ត៌មានថ្មីៗបំផុត ដោយជម្នះលើដែនកំណត់នៃចំណេះដឹងស្ថិតិកក្នុងគំរូដែលបានបណ្តុះបណ្តាលជាមុន។
ខ) សមត្ថភាពក្នុងការចូលប្រើប្រាស់ចំណេះដឹងខាងក្រៅ៖
- RAG អាចចូលប្រើប្រាស់មូលដ្ឋានចំណេះដឹងខាងក្រៅដ៏ធំធេង ដែលលើសពីអ្វីដែលអាចរក្សាទុកក្នុងប៉ារ៉ាម៉ែត្ររបស់ Model តែមួយ។
- នេះអនុញ្ញាតឱ្យមានការឆ្លើយតបកាន់តែទូលំទូលាយ និងចម្រុះជាងមុនក្នុងប្រធានបទជាច្រើន។
គ) ការកាត់បន្ថយការស្រមើស្រមៃ៖
- Language Model ពេលខ្លះបង្កើតព័ត៌មានដែលមើលទៅគួរឱ្យជឿ ប៉ុន្តែមិនត្រឹមត្រូវ (ការស្រមើស្រមៃ)។
- RAG កាត់បន្ថយបញ្ហានេះដោយភ្ជាប់ការឆ្លើយតបទៅនឹងព័ត៌មានពិតដែលបានទាញយក។
៥. ការអនុវត្ត RAG៖ ឧទាហរណ៍សាមញ្ញមួយ
នេះគឺជាការអនុវត្តមូលដ្ឋាននៃ RAG ដោយប្រើ Python៖
import torch
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM
from datasets import load_dataset
import faiss
import numpy as np
# Load pre-trained models
retriever_model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
retriever_tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
generator_model = AutoModelForCausalLM.from_pretrained("gpt2")
generator_tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Load a sample dataset
try:
dataset = load_dataset("wikipedia", "20220301.simple", split="train[:1000]")
except Exception as e:
print(f"Error loading dataset: {e}")
dataset = load_dataset("squad", split="train[:1000]")
Function encode_text:
# Function to encode text into embeddings
def encode_text(text):
inputs = retriever_tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = retriever_model(**inputs)
return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()- Function នេះបំលែងអត្ថបទទៅជា embedding vector។
- វាប្រើ retriever_tokenizer ដើម្បីបំលែងអត្ថបទទៅជា tokens។
- បន្ទាប់មកវាប្រើ retriever_model ដើម្បីបង្កើត embeddings។
- លទ្ធផលគឺជា embedding vector មួយសម្រាប់អត្ថបទដែលបានផ្តល់ឱ្យ។
ការបង្កើត FAISS index:
# Create FAISS index
embeddings = [encode_text(text) for text in dataset["text" if "text" in dataset.column_names else "context"]]
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings))
- បង្កើត embeddings សម្រាប់អត្ថបទទាំងអស់នៅក្នុងសំណុំទិន្នន័យ។
- បង្កើត FAISS index សម្រាប់ការស្វែងរកភាពស្រដៀងគ្នារហ័ស។
RAG:
# RAG function
def rag(query, k=2): # Reduced k from 5 to 2
try:
# Retrieve relevant documents
query_embedding = encode_text(query)
_, indices = index.search(np.array([query_embedding]), k)
retrieved_docs = [dataset["text" if "text" in dataset.column_names else "context"][i] for i in indices[0]]
# Generate response
context = " ".join(retrieved_docs)
input_text = f"Context: {context[:500]}\n\nQuestion: {query}\n\nAnswer:" # Limit context to 500 characters
input_ids = generator_tokenizer.encode(input_text, return_tensors="pt", truncation=True, max_length=1024)
attention_mask = torch.ones_like(input_ids)
pad_token_id = generator_tokenizer.eos_token_id
output = generator_model.generate(
input_ids,
attention_mask=attention_mask,
pad_token_id=pad_token_id,
max_new_tokens=100, # Instead of max_length, use max_new_tokens
num_return_sequences=1,
no_repeat_ngram_size=2
)
response = generator_tokenizer.decode(output[0], skip_special_tokens=True)
return response
except Exception as e:
return f"An error occurred: {str(e)}"- មុខងារនេះអនុវត្តដំណើរការ RAG ពេញលេញ។
- វាទាញយកឯកសារដែលពាក់ព័ន្ធដោយប្រើ FAISS។
- បន្ទាប់មកវាប្រើឯកសារទាំងនេះជាបរិបទសម្រាប់ម៉ូដែល GPT-2។
- វាបង្កើតការឆ្លើយតបដោយផ្អែកលើបរិបទ និងសំណួរ។
- ការបំលែងអត្ថបទទៅជា embeddings។
- ការរក្សាទុក និងស្វែងរក embeddings យ៉ាងមានប្រសិទ្ធភាព។
- ការប្រើព័ត៌មានដែលបានទាញយកដើម្បីបង្កើតការឆ្លើយតប។
វាជាការអនុវត្តមូលដ្ឋាននៃ RAG ដែលអាចត្រូវបានកែលម្អបន្ថែមទៀតសម្រាប់ការប្រើប្រាស់ជាក់ស្តែង។
នេះគឺជាការប្រើប្រាស់ជាក់ស្តែងនៃមុខងារ RAG ដែលយើងបានកំណត់។
# Example usage
query = "What is the capital of France?"
result = rag(query)
print(f"Query: {query}")
print(f"RAG Response: {result}")Output
output:
Query: What is the capital of France?
RAG Response: Context: France ( or ; ), officially the French Republic (, ), is a country whose metropolitan territory is in Western Europe and that also includes various overseas islands and territories in other continents. Metropolitan France extends from the Mediterranean Sea to the English Channel and the North Sea, and from the Rhine to the Atlantic Ocean. It is often referred to as L’Hexagone ("The Hexagon") because of the shape of its territory. France is a unitary semi-presidential republic with its main ideal
Question: What is the capital of France?
Answer: The capital is Paris.៦. ការប្រើប្រាស់ និងការអនុវត្ត
RAG មានការអនុវត្តជាច្រើននៅក្នុងឧស្សាហកម្មផ្សេងៗ៖
ក) Customer service ៖ ផ្តល់ការឆ្លើយតបដែលត្រឹមត្រូវ និងដឹងពីបរិបទចំពោះសំណួររបស់អតិថិជន។
ខ) ការថែទាំសុខភាព៖ ជួយអ្នកជំនាញវេជ្ជសាស្ត្រជាមួយនឹងព័ត៌មាន និងការស្រាវជ្រាវថ្មីៗបំផុត។
គ) ការអប់រំ៖ បង្កើតប្រព័ន្ធរៀនសូត្រដែលអាចសម្របខ្លួនបានដោយមានលទ្ធភាពចូលប្រើប្រាស់មូលដ្ឋានចំណេះដឹងដ៏ធំធេង។
ឃ) ការស្រាវជ្រាវផ្លូវច្បាប់៖ ជួយមេធាវីក្នុងការស្វែងរកច្បាប់ករណី និងឧទាហរណ៍ដែលពាក់ព័ន្ធ។
ង) ការបង្កើតមាតិកា៖ បង្កើតមាតិកាដែលត្រឹមត្រូវតាមការពិត និងបានស្រាវជ្រាវយ៉ាងល្អសម្រាប់គោលបំណងផ្សេងៗ។
ច) ការវិភាគហិរញ្ញវត្ថុ៖ ផ្តល់ការយល់ដឹងដោយផ្អែកលើទិន្នន័យទីផ្សារបច្ចុប្បន្ន។
៧. បញ្ហាប្រឈម និងដែនកំណត់
ខណៈពេលដែល RAG ផ្តល់នូវអត្ថប្រយោជន៍យ៉ាងច្រើន វាក៏ប្រឈមនឹងបញ្ហាមួយចំនួនដែរ៖
ក) ភាពស្មុគស្មាញនៃការគណនា៖ RAG ត្រូវការធនធានគណនាច្រើន។
ខ) គុណភាព និងភាពពាក់ព័ន្ធនៃទិន្នន័យ៖ ប្រសិទ្ធភាពនៃ RAG អាស្រ័យយ៉ាងខ្លាំងលើគុណភាព និងភាពពាក់ព័ន្ធនៃមូលដ្ឋានចំណេះដឹង។
គ) ភាពឯកជន និងសន្តិសុខទិន្នន័យ៖ ការគ្រប់គ្រង និងរក្សាទុកទិន្នន័យក្នុងបរិមាណច្រើនបង្កើតកង្វល់អំពីភាពឯកជន។
Referecnes
- Lewis, P., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf - Borgeaud, S., et al. (2022). Improving language models by retrieving from trillions of tokens. International Conference on Machine Learning, 2206-2240.
https://proceedings.mlr.press/v162/borgeaud22a.html - Izacard, G., & Grave, E. (2021). Leveraging passage retrieval with generative models for open domain question answering. EACL 2021.
https://aclanthology.org/2021.eacl-main.74/ - Guu, K., et al. (2020). Retrieval augmented language model pre-training. International Conference on Machine Learning, 3929-3938.
https://proceedings.mlr.press/v119/guu20a.html - Petroni, F., et al. (2019). Language models as knowledge bases?. EMNLP-IJCNLP 2019.
https://aclanthology.org/D19-1250/ - Karpukhin, V., et al. (2020). Dense passage retrieval for open-domain question answering. EMNLP 2020.
https://aclanthology.org/2020.emnlp-main.550/ - Hugging Face Documentation: Retrieval Augmented Generation (RAG)
https://huggingface.co/docs/transformers/model_doc/rag - Liu, W., et al. (2023). Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Computing Surveys.
https://arxiv.org/abs/2107.13586 - Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR 2020.
https://dl.acm.org/doi/10.1145/3397271.3401075 - Shuster, K., et al. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv preprint.
https://arxiv.org/abs/2005.11401
These references provide a comprehensive overview of RAG and related techniques, covering both theoretical foundations and practical implementations. They should serve as excellent resources for further research on the topic.