
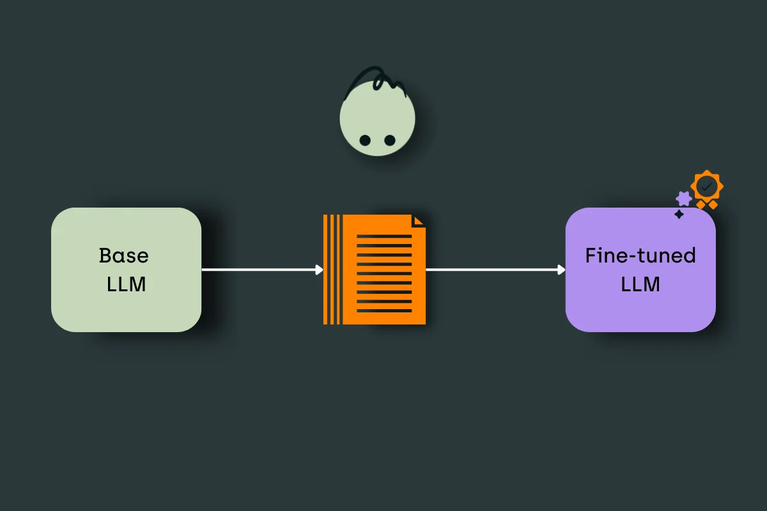
តើអ្វីទៅជា Fine-tuning?
Fine-tuning គឺជាបច្ចេកទេសមួយក្នុង Machine Learning ដែលគេប្រើដើម្បីកែលម្អម៉ូដែលដែលបាន Train រួចហើយ ដោយប្រើប្រាស់ទិន្នន័យជាក់លាក់សម្រាប់ភារកិច្ចឬដែនជាក់លាក់មួយ។ វាជាដំណើរការនៃការសម្របសម្រួលម៉ូដែលដែលមានស្រាប់ ដើម្បីឱ្យវាអាចដំណើរការបានល្អប្រសើរលើភារកិច្ចជាក់លាក់ណាមួយ។
ចំណុចសំខាន់ៗនៃ Fine-tuning:
- ការប្រើប្រាស់ម៉ូដែលដែលបានបណ្តុះបណ្តាលជាមុន: Fine-tuning ចាប់ផ្តើមជាមួយម៉ូដែលដែលបានបណ្តុះបណ្តាលរួចហើយលើសំណុំទិន្នន័យធំ។
- ការបណ្តុះបណ្តាលបន្ថែម: ម៉ូដែលនេះត្រូវបានបណ្តុះបណ្តាលបន្ថែមលើសំណុំទិន្នន័យតូចជាងមុន ប៉ុន្តែជាក់លាក់សម្រាប់ភារកិច្ចឬដែនជាក់លាក់។
- ការរក្សាចំណេះដឹងដើម: Fine-tuning រក្សាចំណេះដឹងទូទៅដែលម៉ូដែលបានរៀនពីមុន ខណៈពេលដែលកែសម្រួលវាសម្រាប់ភារកិច្ចថ្មី។
- ការសន្សំសំចៃធនធាន: វាត្រូវការពេលវេលា និងទិន្នន័យតិចជាងការបណ្តុះបណ្តាលម៉ូដែលពីសូន្យ។
ហេតុអ្វីបានជា Fine-tuning មានសារៈសំខាន់?
- ការបង្កើនប្រសិទ្ធភាព: វាអាចបង្កើនប្រសិទ្ធភាពរបស់ម៉ូដែលលើភារកិច្ចជាក់លាក់។
- ការសម្របខ្លួនទៅនឹងដែន: វាអនុញ្ញាតឱ្យម៉ូដែលសម្របខ្លួនទៅនឹងភាសា ឬពាក្យពេចន៍ជាក់លាក់នៃឧស្សាហកម្មឬដែនណាមួយ។
- ការប្រើប្រាស់ធនធានតិច: វាមានប្រសិទ្ធភាពជាងការបណ្តុះបណ្តាលម៉ូដែលពីសូន្យ។
- ការអនុវត្តលឿន: វាអនុញ្ញាតឱ្យអ្នកអភិវឌ្ឍន៍បង្កើតម៉ូដែលដែលមានប្រសិទ្ធភាពខ្ពស់ក្នុងរយៈពេលខ្លី។
Fine-tuning ត្រូវបានប្រើប្រាស់យ៉ាងទូលំទូលាយក្នុងការរៀនម៉ាស៊ីន ជាពិសេសក្នុង Natural Language Processing (NLP) សម្រាប់ភារកិច្ចដូចជាការវិភាគអារម្មណ៍ ការឆ្លើយសំណួរ និងការបកប្រែភាសា។
ឧទាហរណ៍កូដ
- ក្នុងការណែនាំនេះ យើងនឹងឆ្លងកាត់ដំណើរការនៃការ Fine-tune នូវម៉ូដែល GPT-2 លើសំណុំទិន្នន័យផ្ទាល់ខ្លួន ដោយប្រើប្រាស់ Library Hugging Face Transformers។
- សម្រាប់ឧទាហរណ៍នេះ យើងនឹងប្រើសំណុំរងនៃសំណុំទិន្នន័យ “emotion” ពី Library សំណុំទិន្នន័យរបស់ Hugging Face។ សំណុំទិន្នន័យនេះមានសារអត្ថបទខ្លីៗដែលបានដាក់ស្លាកជាមួយអារម្មណ៍។
- ជាដំបូង សូមដំឡើង Library ដែលត្រូវការ៖
!pip install transformers datasets torch
!pip install transformers[torch] -U
!pip install accelerate -Uនេះគឺជាស្គ្រីប Python ដែលបង្ហាញពីដំណើរការ Fine-tuning៖
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer, DataCollatorForLanguageModeling
from transformers import Trainer, TrainingArguments
from datasets import load_dataset
# Load pre-trained model and tokenizer
model_name = "gpt2"
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
# Set padding token
tokenizer.pad_token = tokenizer.eos_token
# Load and preprocess the dataset
dataset = load_dataset("emotion", split="train")
def preprocess_function(examples):
return tokenizer([f"Emotion: {text}" for text in examples["text"]], truncation=True, padding="max_length", max_length=64)
tokenized_dataset = dataset.map(preprocess_function, batched=True, remove_columns=dataset.column_names)
# Convert to PyTorch tensors
tokenized_dataset.set_format("torch")
# Create DataCollator
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# Define training arguments
training_args = TrainingArguments(
output_dir="./gpt2-emotion-finetuned",
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=10_000,
save_total_limit=2,
)
# Create Trainer
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_dataset,
)
# Fine-tune the model
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./gpt2-emotion-finetuned")
tokenizer.save_pretrained("./gpt2-emotion-finetuned")បន្ទាប់ពីការ Fine-tune អ្នកអាចប្រើម៉ូដែលដើម្បីបង្កើតអត្ថបទដោយផ្អែកលើអារម្មណ៍៖
# Load the fine-tuned model and tokenizer
fine_tuned_model = GPT2LMHeadModel.from_pretrained("./gpt2-emotion-finetuned")
fine_tuned_tokenizer = GPT2Tokenizer.from_pretrained("./gpt2-emotion-finetuned")
# បង្កើតអត្ថបទ
prompt = "Emotion: i didnt feel well"
input_ids = fine_tuned_tokenizer.encode(prompt, return_tensors="pt")
output = fine_tuned_model.generate(input_ids, max_length=100, num_return_sequences=1, no_repeat_ngram_size=2)
generated_text = fine_tuned_tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)Output
Emotion: i didnt feel well enough to go to the doctor but i was feeling good enough that i could go for a walk and not feel so bad about it all the time and that was good for me too because i had been feeling pretty good about my health for the past week and a half and i just needed to get through it without feeling like i got a bad grade or something and then i would be fine again and again until i went to my doctor and got my results and it wasឧទាហរណ៍នេះបង្ហាញពីរបៀបធ្វើឱ្យប្រសើរឡើងនូវ GPT-2 លើសំណុំទិន្នន័យ “emotion” និងប្រើវាដើម្បីបង្កើតអត្ថបទដែលផ្អែកលើអារម្មណ៍។ សូមចងចាំថាត្រូវកែសម្រួលប៉ារ៉ាម៉ែត្រ និងទំហំសំណុំទិន្នន័យទៅតាមតម្រូវការជាក់លាក់របស់អ្នក និងធនធានគណនាដែលមាន។
References
1. Hugging Face Transformers Library Documentation:
- Main documentation: https://huggingface.co/transformers/
- Fine-tuning tutorial: https://huggingface.co/transformers/training.html
2. GPT-2 Model:
- Model card: https://huggingface.co/gpt2
3. Datasets Library:
- Main documentation: https://huggingface.co/docs/datasets/
- Emotion dataset: https://huggingface.co/datasets/emotion
- Hugging Face's language modeling example:
https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling
- Fine-tuning GPT-2 for text generation tutorial:
https://huggingface.co/blog/how-to-generate